I am using the REBEL model from the hugging face library. The REBEL model performs both NER and Relation Extraction. It takes input as a sentence and outputs a triple {head, type, tail}. Here I set the n as 10, so for a single sentence, 10 iterations of NER and RE are performed. Each iteration extracts the triples, we can notice that there can be multiple instances of a single triple in a different iteration. To know more about the REBEL model, you can refer to the paper here.
How each triple is extracted?
For RE, we want to express triplets as a sequence of tokens such that we can retrieve the original relations and minimize the number of tokens to be generated so as to make decoding more efficient. We introduce a set of new tokens, as markers, to achieve the aforementioned linearization.
Datasets in REBEL
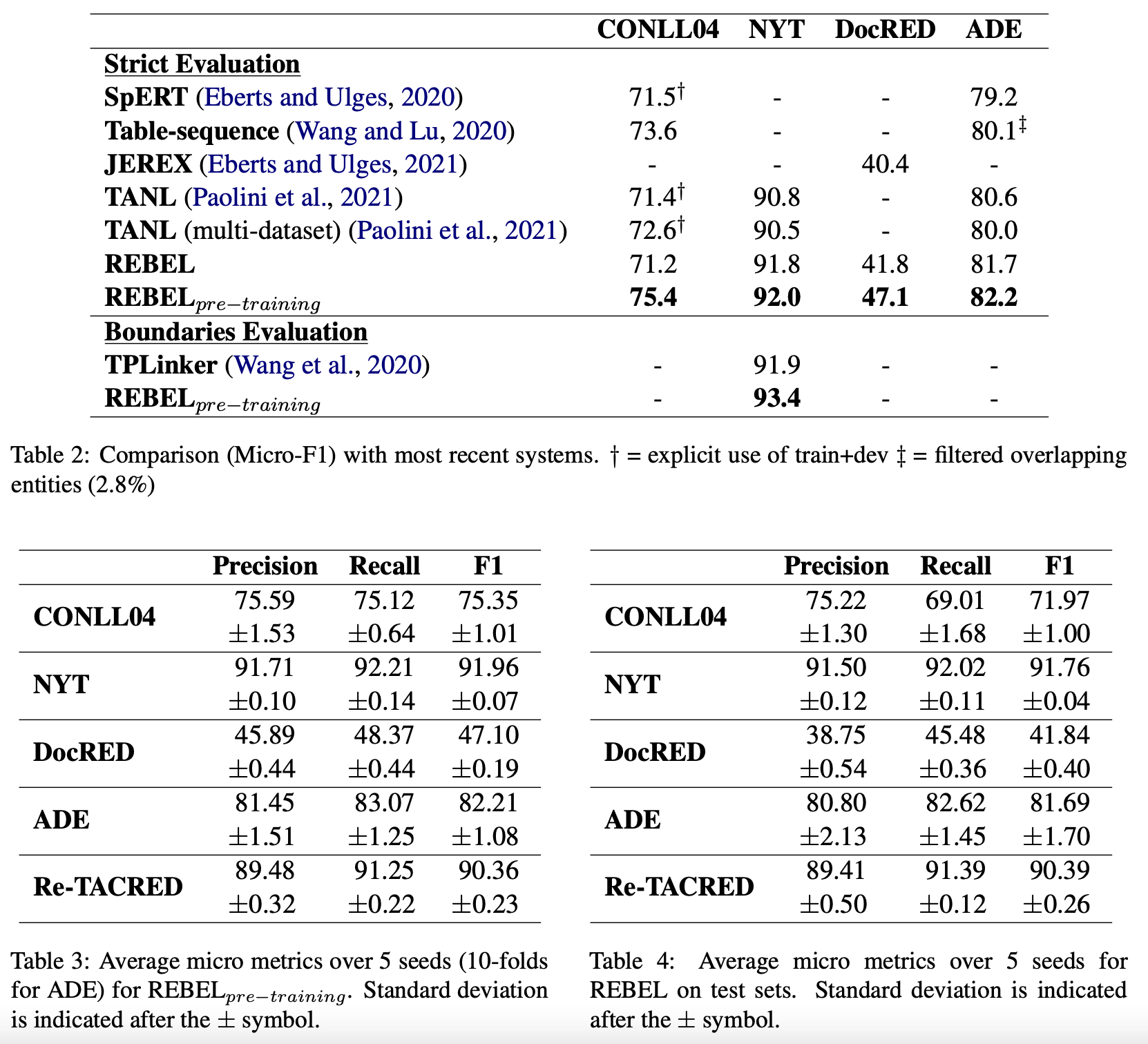
The dataset is created by distant supervision and serves as a pre-training step, however, it is worth noting its performance for predicting up to 220 different relation types.
| Dataset Details | |
|---|---|
| REBEL dataset | This dataset was created by matching Wikipedia hyperlinks with Wikidata entities. To pre-train model, a sentence- level version is used for it, where only relations between entities present in each sentence are kept. The 220 most frequent relations in the train split |
| CONLL04 | CONLL04 (Roth and Yih, 2004) is composed of sentences from news articles, annotated with four entity types (person, organization, location and other) and five relation types (kill, work for, or- ganization based in, live in and located in) |
| DocRED | DocRED (Yao et al., 2019) is a recent dataset cre- ated similarly to our pre-training data, by leverag- ing Wikipedia and Wikidata. However, it focuses on longer spans of text, with relations between entities at a document level. There is a distantly su- pervised portion, while the validation and (hidden) test sets are manually annotated. It includes anno- tations for 6 different entity types and 96 relation types. |
| NYT | NYT (Riedel et al., 2010) is a dataset consisting of news sentences from the New York Times corpus. The dataset contains distantly annotated relations using FreeBase. We use the processed version of Zeng et al. (2018) called NYT-multi, which con- tains overlapping entities, with three different entity types, and 24 relation types. |
| ADE | ADE (Gurulingappa et al., 2012) is a dataset on the biomedical domain, for which Adverse-Effects from drugs are annotated as pairs of drug and adverse-effect. The dataset provides 10-folds of train and test splits. |
| Re-TACRED | Re-TACRED (Stoica et al., 2021) is a Relation Clas- sification dataset, a revised version of the widely used TACRED (Zhang et al., 2017), fixing some of the issues pointed out by Alt et al. (2020). We want to extract the relation between two given entities, or the no_relation prediction, accounting for 63% of the 91,467 sentences in the dataset. |
Methodology
Sentence: in the short term, common side effects of paracetamol are nausea and abdominal pain, and it seems to have tolerability similar to ibuprofen.
Then we calculate the confidence level of each triple:
Count(unique Triple)/Count(all the triples)
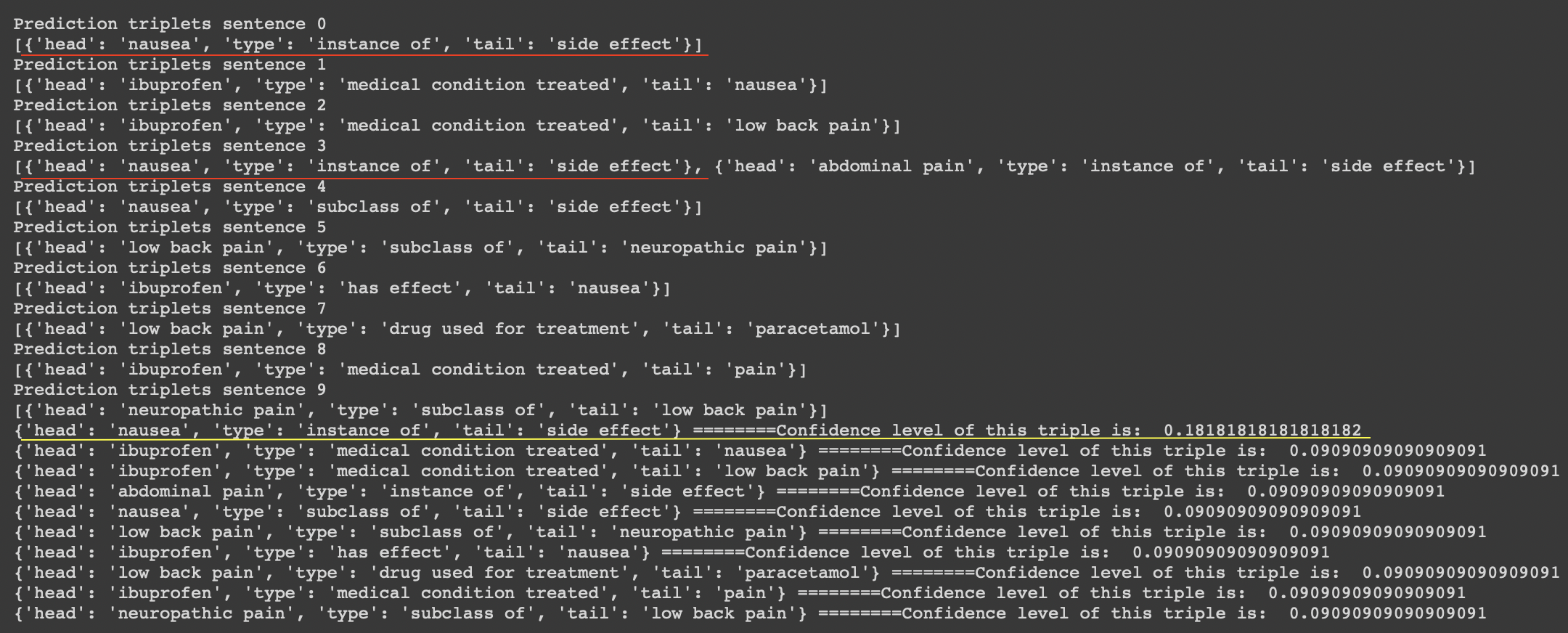
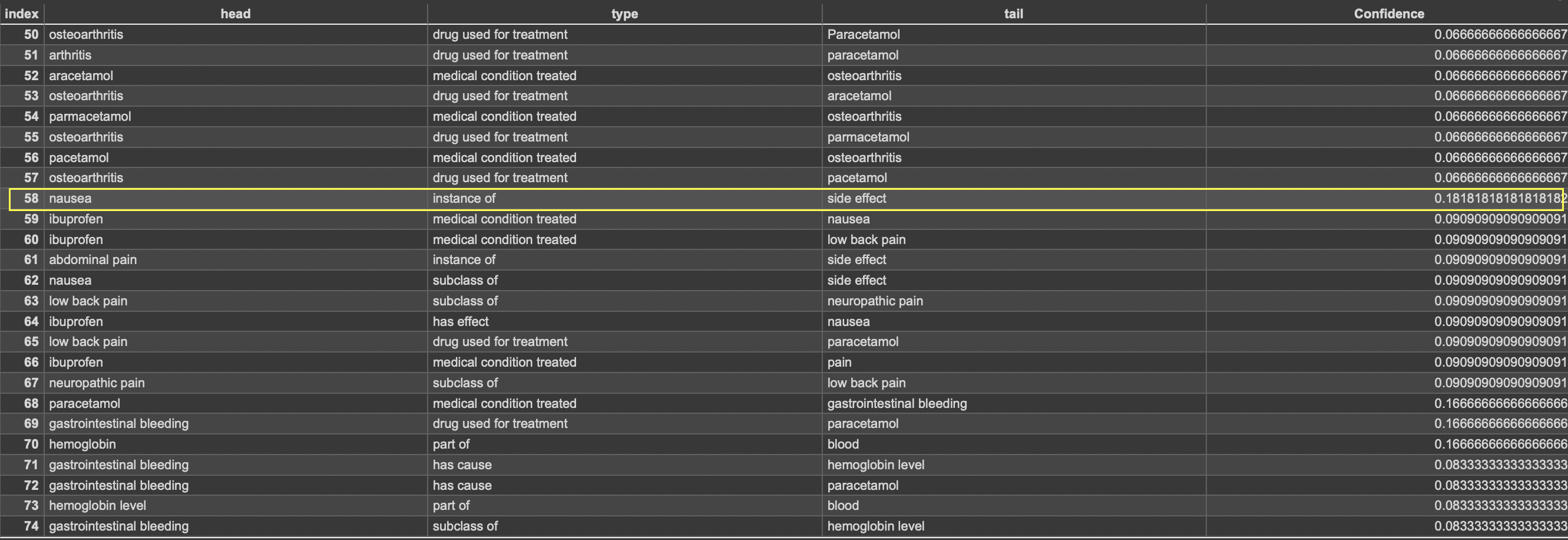
We can discard triples which are having confidence level below a certain threshold.
I got the Wikipedia page links present in a particular Wikipedia article by using the following SPARQL query:
select ?link ?pred ?pred_inv where {
<http://dbpedia.org/resource/Berlin_Wall> <http://dbpedia.org/ontology/wikiPageWikiLink> ?link .
optional {
<http://dbpedia.org/resource/Berlin_Wall> ?pred ?link
filter(?pred != <http://dbpedia.org/ontology/wikiPageWikiLink>)
}
optional {
?link ?pred_inv <http://dbpedia.org/resource/Berlin_Wall>
filter(?pred_inv != <http://dbpedia.org/ontology/wikiPageWikiLink>)
}
} order by ?link
I scraped the whole Wikipedia article using the Wikipedia python library and then performed coreference resolution on the text using the neuralcoref library.
By using the Wikipedia library of python, I extracted all the URLs(around 1500 URLs) and the corresponding text anchored to the URL and stored it in a list of multiple dictionaries.
Now I matched the URLs in these 2 lists, however out of 310 URLs(in DBpedia one) only 280 were matched.
Reasons for difference in URL:
- For words with diacritical marks. The issue of URLs with Diacritical marks was removed by decoding UTF8.
- Redirect links

- No article present for the corresponding entity
Now I have a list of 280 URLs and the corresponding anchored text.
And I have a table of triple which contain the entities and the relation.
Now I match the entities to their corresponding URL if the entity is present in the list for the anchored text and corresponding URL.
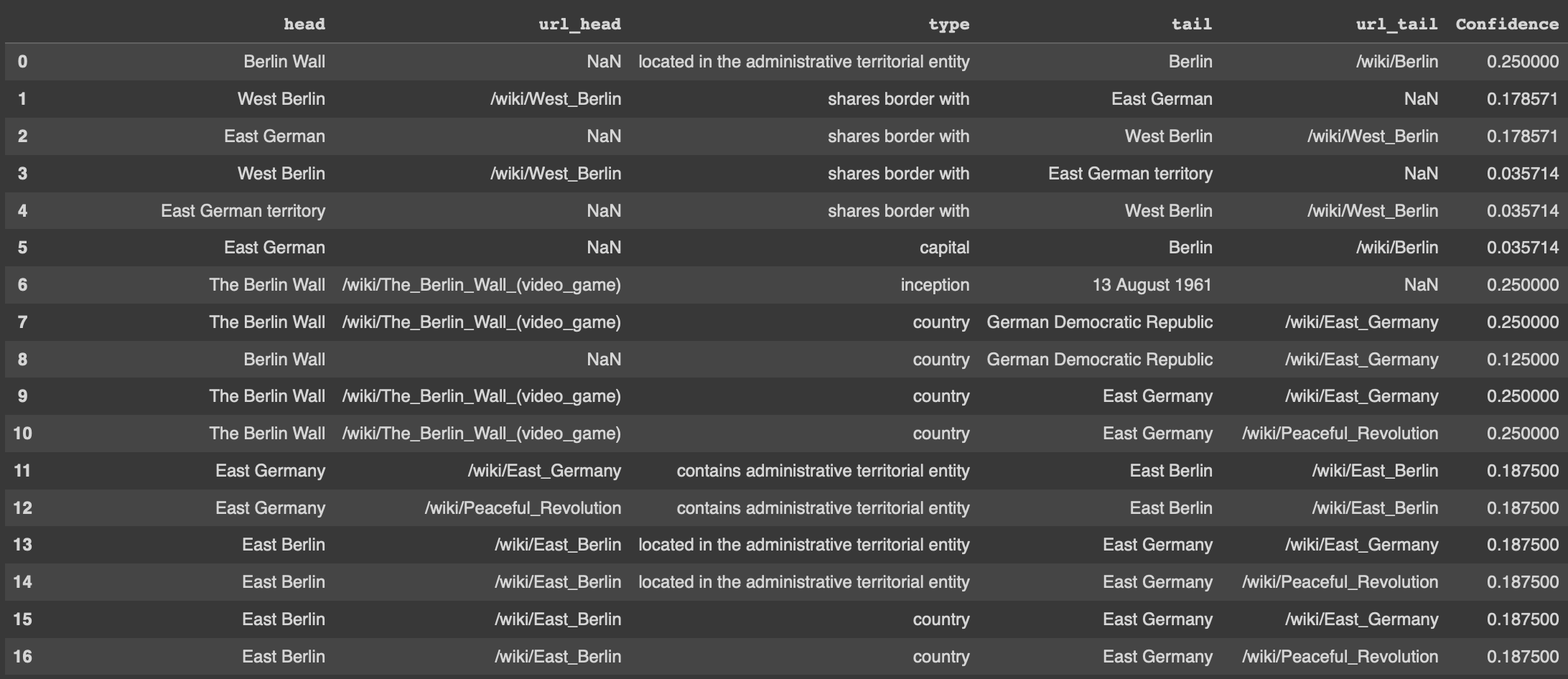
Please note that we can have a single URL mapped to multiple texts and multiple instances of the same dictionary consisting of the URL and the text it is anchored to. I performed a left join on the table to get the URL for the head entity and after that, a right join to get the URL for the tail entities. Here we can do one more thing is that we can check for the entities and their corresponding URLs on Wikipedia.
 Please note: It only works for the English language Wikipedia articles and the Triple extraction is carried out only for the first 10 sentences since it takes some time to execute. But you can increase the number of sentences for which you want to extract the triples by changing the number of iterations to the length of the list containing all the sentences present in the article. You can also change the value of parameters: “num_beams”: 10,
“num_return_sequences”: 10
Please note: It only works for the English language Wikipedia articles and the Triple extraction is carried out only for the first 10 sentences since it takes some time to execute. But you can increase the number of sentences for which you want to extract the triples by changing the number of iterations to the length of the list containing all the sentences present in the article. You can also change the value of parameters: “num_beams”: 10,
“num_return_sequences”: 10
Summary of the project tasks
- Scraped the text from the Wikipedia article
- Performed Coreference Resolution
- Tokenised articles into Sentences
- REBEL model is run on each Sentence
- The confidence level for each triple is calculated
- Corresponding Head and Tail entities are matched to their respective URLs
My Takeaways
I went through many research papers. Learnt a lot about different ways to do Relation extract from normal rule-based to Distant supervision, dependency Parsing, Named entity Recognition, Coreference Resolution, Reverb model, OpenNRE model, REBEL model, etc.
This Project helped me identify my interest in the field of NLP and it was my first major contribution to the Open Source Community.
Future Goals
I would continue contributing to the Neural Extraction Framework Project
- Storing triples in a Graph Database
- If a pronoun text is anchored to a URL(relatively very few instances) then we miss out on those URLs while matching it in the coreference resolved text. For this, we can use a list to store such instances.
- Making coreference resolution better
- Extracting all the correct URLs corresponding to the entities
I would love to build a model that could predict a new relation after accomplishing the above tasks.
Overall, it was an amazing and enriching experience for me, I got to learn a lot during GSoC. My all mentors were highly supportive, and knowledgeable and guided me along the path. I look forward to working and learning with them.
Link to the repositary: https://github.com/dbpedia/neural-extraction-framework/tree/gsoc22-ananya