This week I did and have to continue with the following tasks:
- Extract the anchored text to the hyperlink
- Scraping all the text from the Wikipedia article
- Coreference Resolution
- Tokenising text into sentences
- Storing sentences in a dataframe with the position of the head and tail entity stored in the other column
- Applying the OpenNRE model for the sentence-level relation extraction, appending the relation column in the dataframe, predicting the top 3 relation
Extracting Anchored text
the <a href="/wiki/United_Kingdom_of_Great_Britain_and_Northern_Ireland" class="mw-redirect" title="United Kingdom of Great Britain and Northern Ireland">United Kingdom</a>, <a href="/wiki/France" title="France">France</a> and the <a href="/wiki/Soviet_Union" title="Soviet Union">Soviet Union</a>. The capital of Berlin, as the seat of the <a href="/wiki/Allied_Control_Council" title="Allied Control Council">Allied Control Council</a>, was similarly subdivided into four sectors despite the city's location, which was fully within the Soviet zone.
the United Kingdom, France and the Soviet Union. The capital of Berlin, as the seat of the Allied Control Council, was similarly subdivided into four sectors despite the city’s location, which was fully within the Soviet zone.
Here you can see that the article having title United Kingdom of Great Britain and Northern Ireland and URL:wiki/United_Kingdom_of_Great_Britain_and_Northern_Ireland is anchored to the text United Kingdom
In the wikipedia article there are around 2500 links extracted, but the SPARQL query where we used the wikipageWikilink property, around 308 links were extracted.
I thought that the 308 links are a proper subset of those 2500 links, and it is true but when I matched for the links in both, I got 430 links because some were repetitive hyperlinks, i.e. multiple instances of the same entity in the article and may or may not be anchored to the same text.
Initially, Around 250 unique links were there with the anchored text.
The rest 58 links were not taken into account because:
- Either they are redirected to a link
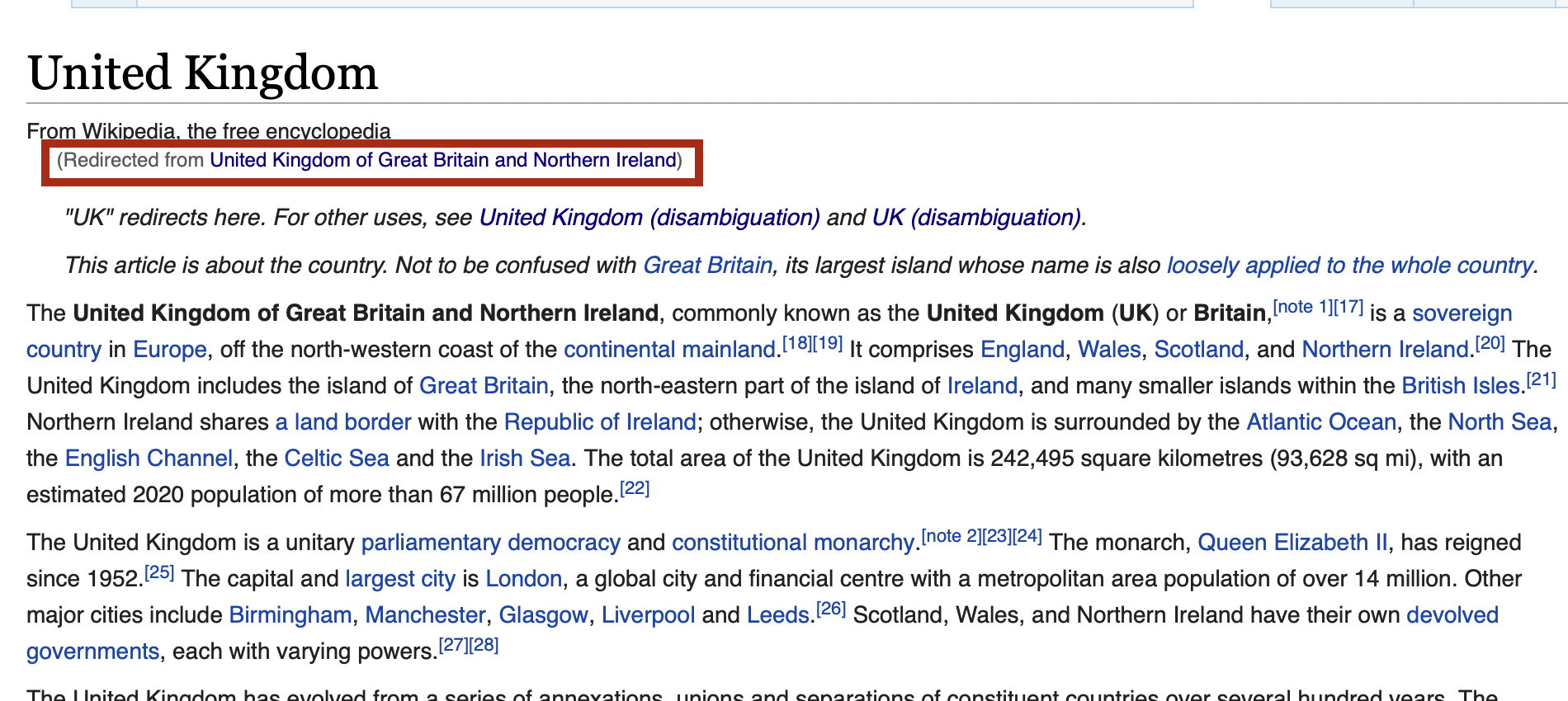 Fig1
Fig1
- or their page doesn’t exist
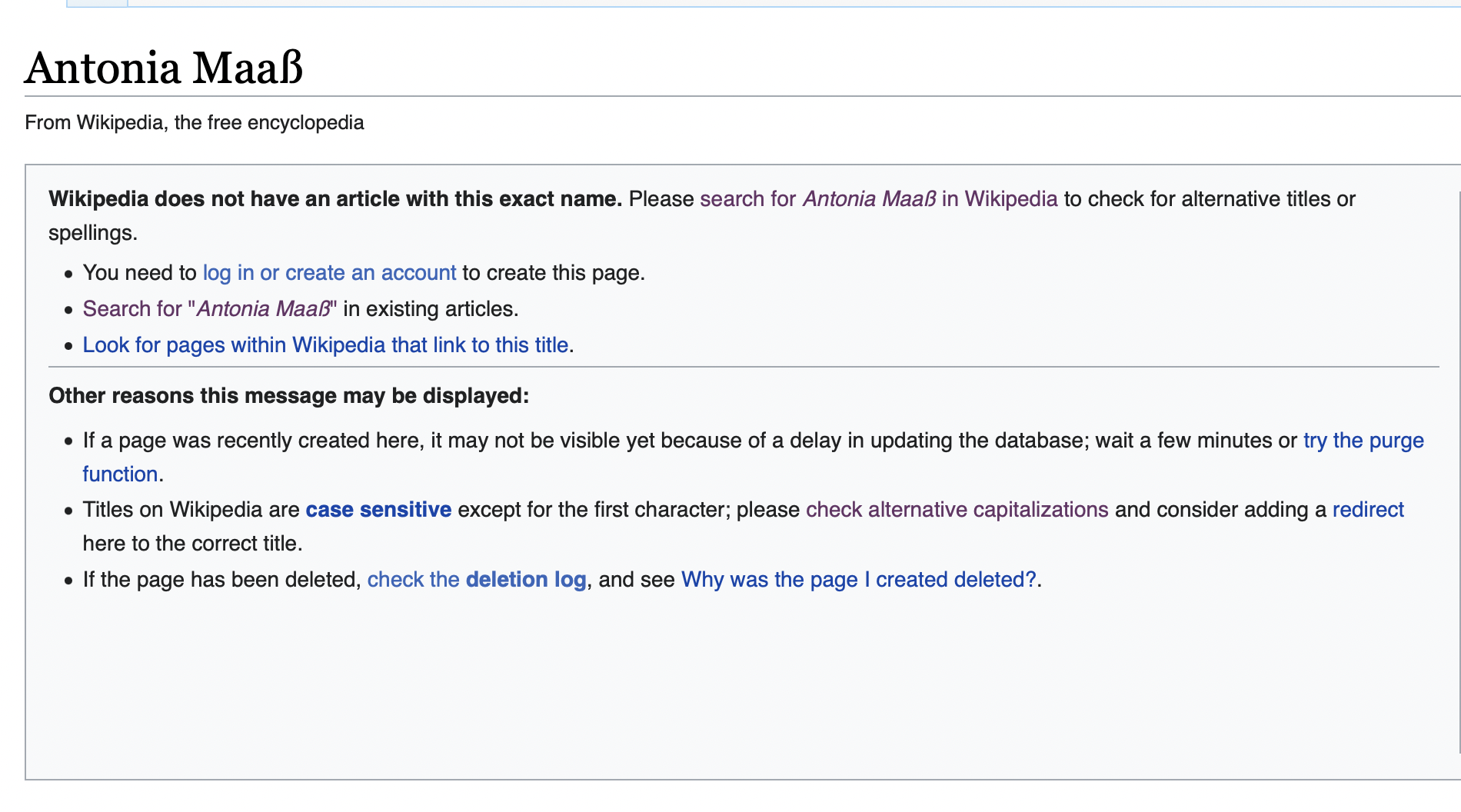 Fig2
Fig2
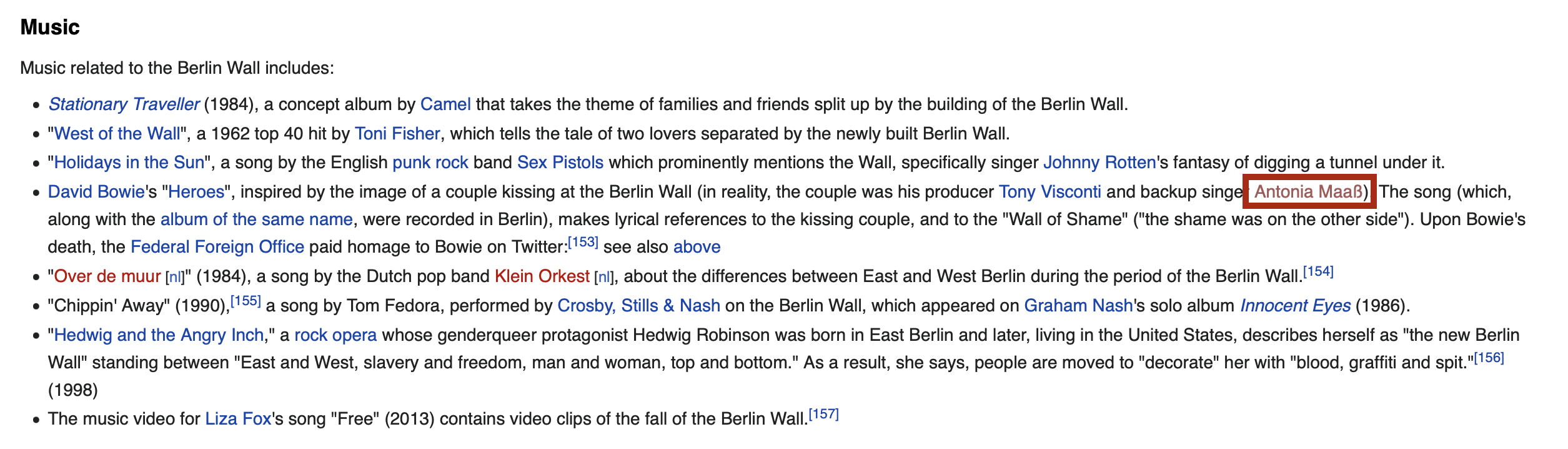 Fig3
Fig3
- or there are some words with diacritical marks that were not being matched in the extracted links through the Wikipedia article and the SPARQL query.
SPARQL: /wiki/Großbeeren
WIKIPEDIA: {'url': '/wiki/Gro%C3%9Fbeeren', 'text': 'Großbeeren'}
To resolve the issue of diacritical marks I decoded the URL, and now I was getting around 280 links.
I have to look into account the rest 38 links, and how to extract them. One thing in my mind as of now is redirected URLs have class=”mw-redirect” with the href tag, I can use the MediaWiki API to get the URL of the redirected article. And for the article Wikipedia page doesn’t exist, those articles are not of much significance to us.
Text scraping
All the text was also scraped from the article using the Wikipedia library. Wikipedia.content gave all the content of the Wikipedia article. I got heading along with the scraped text enclosed between === heading ===.
I have to clean the scraped text a bit, and remove new line characters and some escape characters.
Since initially I am doing sentence-level relation extraction, hence the text like this in a Wikipedia article:
Following are the causes of World war II:
- Treaty of Versailles
- France occupying a resource-rich area of Germany
- Hurting sentiments of German people
We can find such patterns as <li> tags preceeded by a colon(:) or a newline character(\n) preceeded by a colon(:).
For relation extraction purposes this text should be restructured like this:
Treaty of Versailles is the cause of World war II. France occupying a resource-rich area of Germany is the cause of World war II. Hurting the sentiments of the German people is the cause of World war II.
Coreference resolution
Coreference resolution is the task of finding all expressions that refer to the same entity in a text. I have to use coreference resolution so that entities are captured and the context becomes easier to grasp.
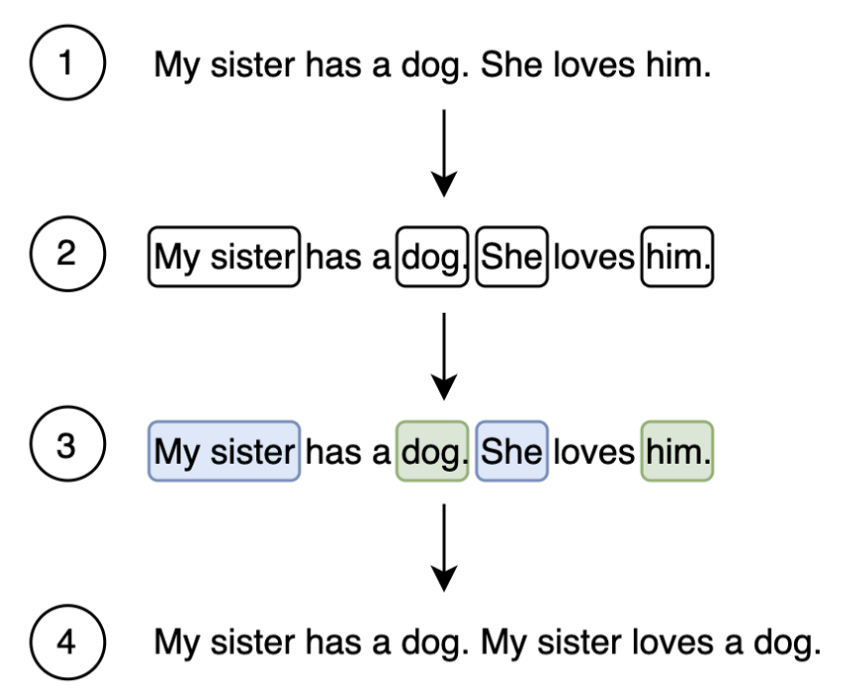 Fig4
Fig4
In easy words, replacing the pronouns with nouns as I am doing sentence-level relation extraction.
But I believe there is a problem with coreference resolution for the whole article. In some cases a hyperlink might be anchored with a pronoun for instance it and if I perform coreference resolution then it might get replaced with some noun hence being unable to get the hyperlink to which previously pronoun it and now the noun is linked to. It can be done if we store both the pronoun and then attach the corresponding noun and hence not lose the hyperlink the noun is now anchored to.
One more thing to be taken into account is that the base article is sometimes referred to with other names in the article too.
For e.g.
Berlin Wall is referred to as The wall in the article Barack Obama is referred to as Obama, Barrack Hussein Obama II, The first Black President of the USA in the article
Tokenisation of text into sentences
- Getting all the sentences which contain the entities and their context and removing all other sentences from the text.
- Storing it in the pandas dataframe with the columns for sentence, entities present, and position of head and tail entities. (Some sentences might have more than 2 entities, have to look)
For tokenisation into sentences, the SpaCy library can be used.
OpenNRE
I plan to do relation extraction with the help of the OpenNRE framework initially. Sentence level relation extraction using wiki80 dataset with 80 classes(relations) and 56,000 instances.
OpenNRE has the following released models for sentence-level relation extraction:
- wiki80_cnn_softmax: trained on wiki80 dataset with a CNN encoder.
- wiki80_bert_softmax: trained on wiki80 dataset with a BERT encoder.
- wiki80_bertentity_softmax: trained on wiki80 dataset with a BIRT encoder.
After installing OpenNRE, open Python and load OpenNRE:
>>> import opennre
Then load the model with its corresponding name:
>>> model = opennre.get_model('wiki80_cnn_softmax')
After loading it, you can do relation extraction with the following format:
>>> model.infer({'text': 'He was the son of Máel Dúin mac Máele Fithrich, and grandson of the high king Áed Uaridnach (died 612).', 'h': {'pos': (18, 46)}, 't': {'pos': (78, 91)}})
The infer function takes one dict as input. The text key represents the sentence and the h/ t keys represent head and tail entities, in which pos (position) should be specified.
The model will return the predicted result as:
>>> ('father', 0.5108704566955566)
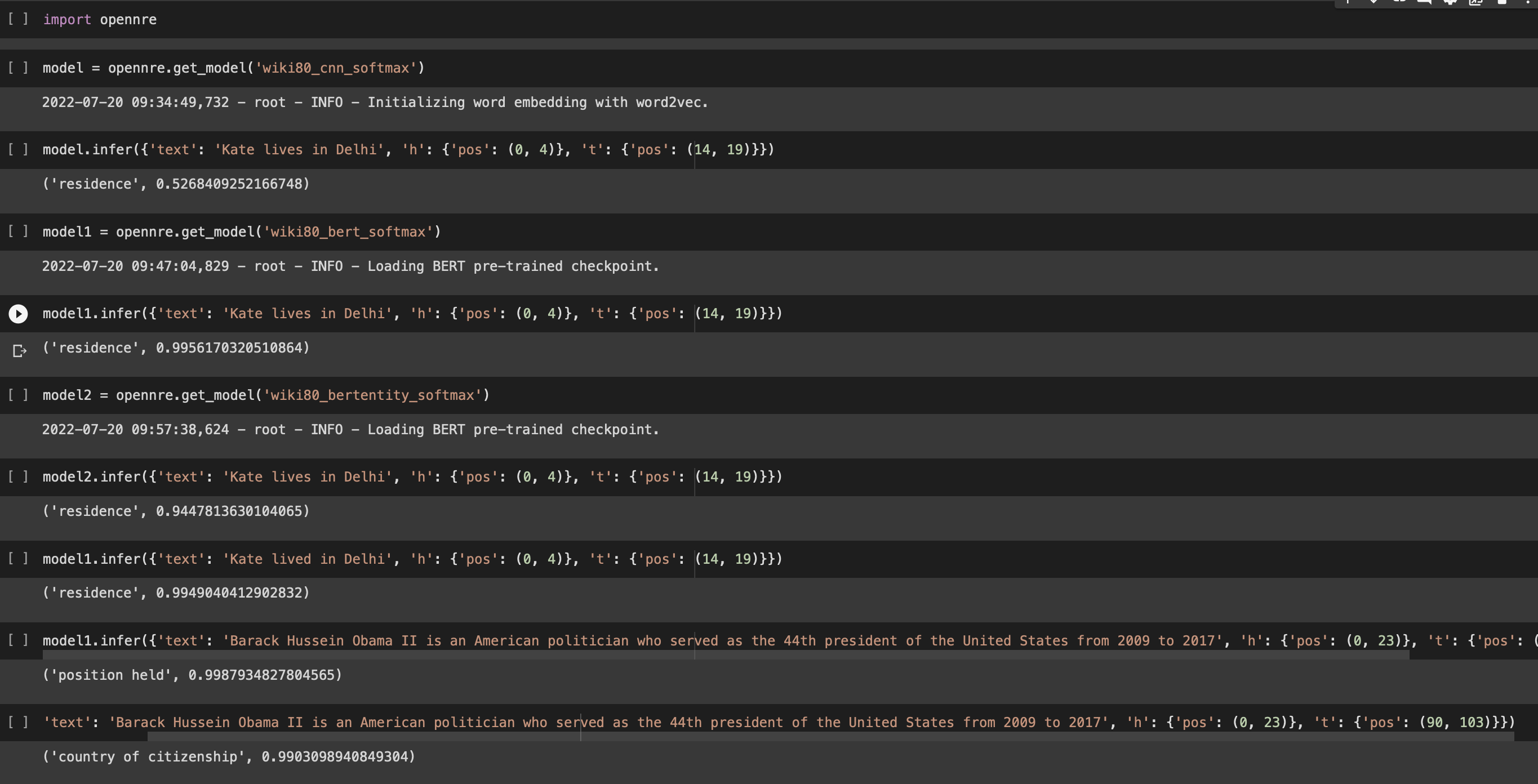 Fig5
Fig5
Ponder
One thing to be noticed is whether the sentence is Kate lives in Delhi or Kate lived in Delhi, both extract the relation {residence}.