There is a small difference between the relation extraction seen conventionally and our problem statement. The difference is normal relation extraction we are given a sentence, first we have to find entities in the sentence, and the sentence can have multiple entities and
In our case entities already extracted, now we have to find relation.
In most papers for Information extraction, it is given that NER is taken place first and then RE.
In our case we have to label entities as ORG, PERSON, LOC, etc.
Challenges
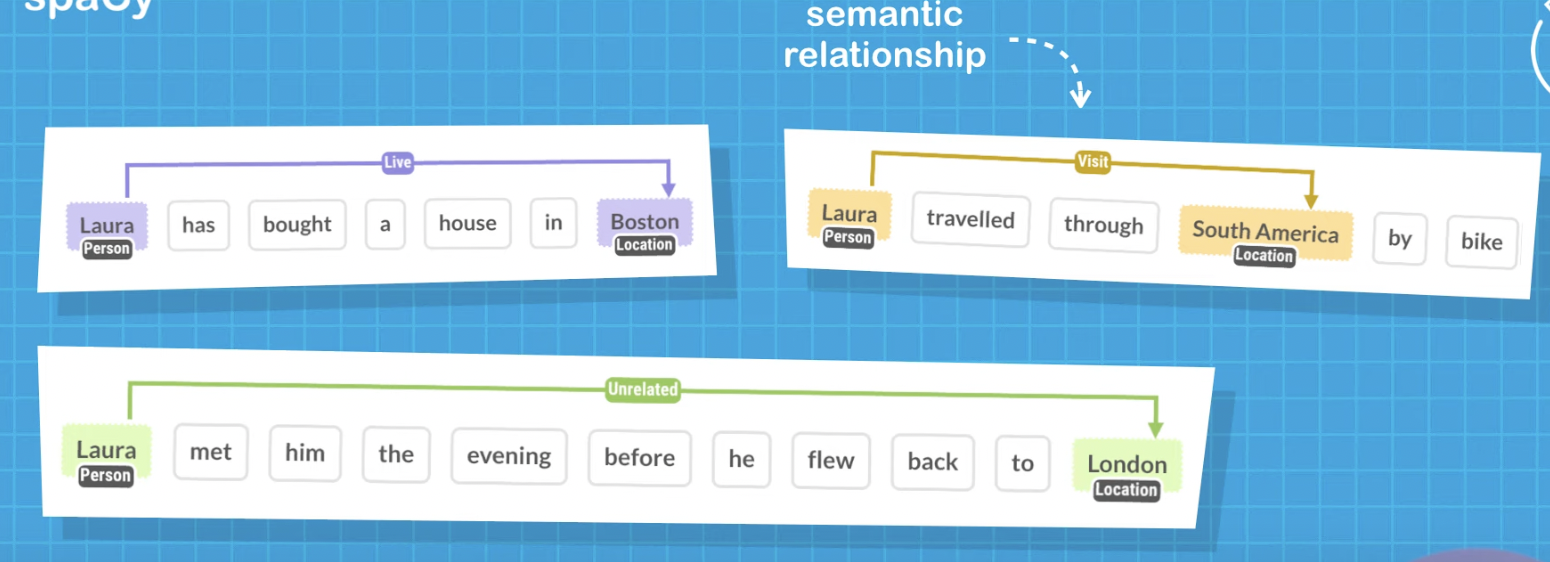
Extracting RDF triples from the unstructured part of Wikipedia articles. For example, in the Wikipedia article of Barack Obama it is mentioned that:
Obama is a supporter of the Chicago White Sox
This information can be represented as the following triple: cr>BarackObama</span> supporterOf ChicagoWhiteSox. Such triple can then be added to any existing data source.
The main challenge in this work is that there are two different problems that need to be simultaneously dealt with. The first is the relation extraction (RE) problem, that is, given a text containing entities, we syntactically extract relations between them. The second is the knowledge representation (KR) problem, that is, the extracted relations should always follow a well-defined schema, semantics, or ontology. This is an important issue because we want to combine all the extracted relations to enrich existing data sources. Without handling the knowledge representation properly, one can just extract all possible relations without considering whether, for example, two relations are equivalent and should be merged together, or whether additional semantic details can be mined from the sentence in order to correctly represent a more complex fact.
In the same article, it is also mentioned that
In his childhood and adolescence, he was a fan of the Pittsburgh Steelers
From the sentence, let us extract the following triple: BarackObama fanOf PittsburghSteelers. From the extraction point of view, the result is already correct. However, from the KR point of view it is not good enough. First, because the predicate supporterOf and fanOf are equivalent in this context and should be merged. Second, since Obama was a fan of Pittsburgh Steelers in his childhood, it is suggested that the fact happened in the past and therefore adding time information in the representation is necessary to differentiate it with the first example. Now, the next challenge is how we represent a complex fact. One solution is that we append time information into the predicate, resulting in wasFanOf, and then we specify the sub-predicate relation between wasFanOf and fanOf. Another solution is that we keep using fanOf, and then we leverage RDF reification to append time information as a separate triple. There may be other possible solutions, and deciding which one is the best is most of the times difficult.
Approaches
The thing with distant supervision is new relation can’t be found. And there can be negative instances also. For e.g.
Elon musk gave suggestions on how to make SpaceX a successful company.
Here relation extracted by distant supervision would be {owner_of, elon_musk, SpaceX} which is not the case in the above sentence.
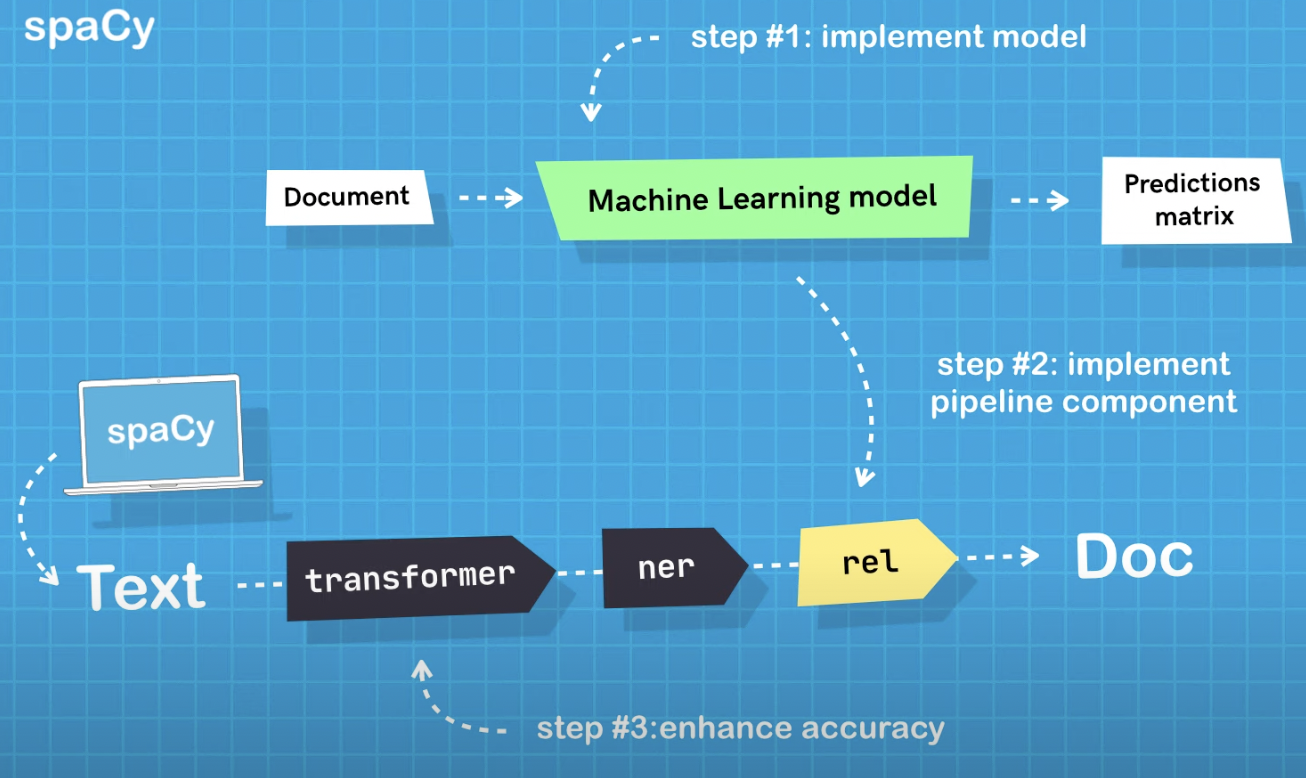
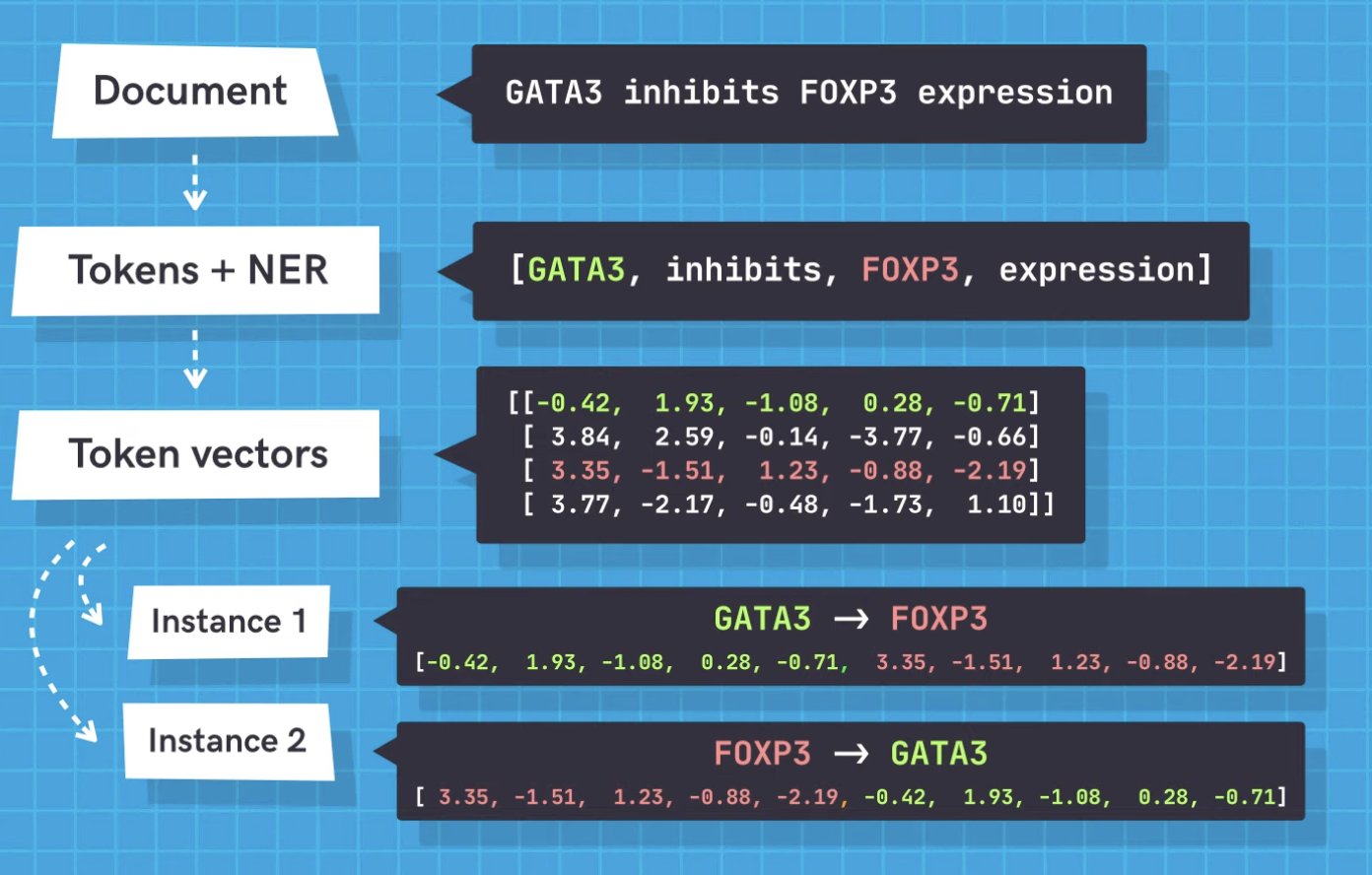
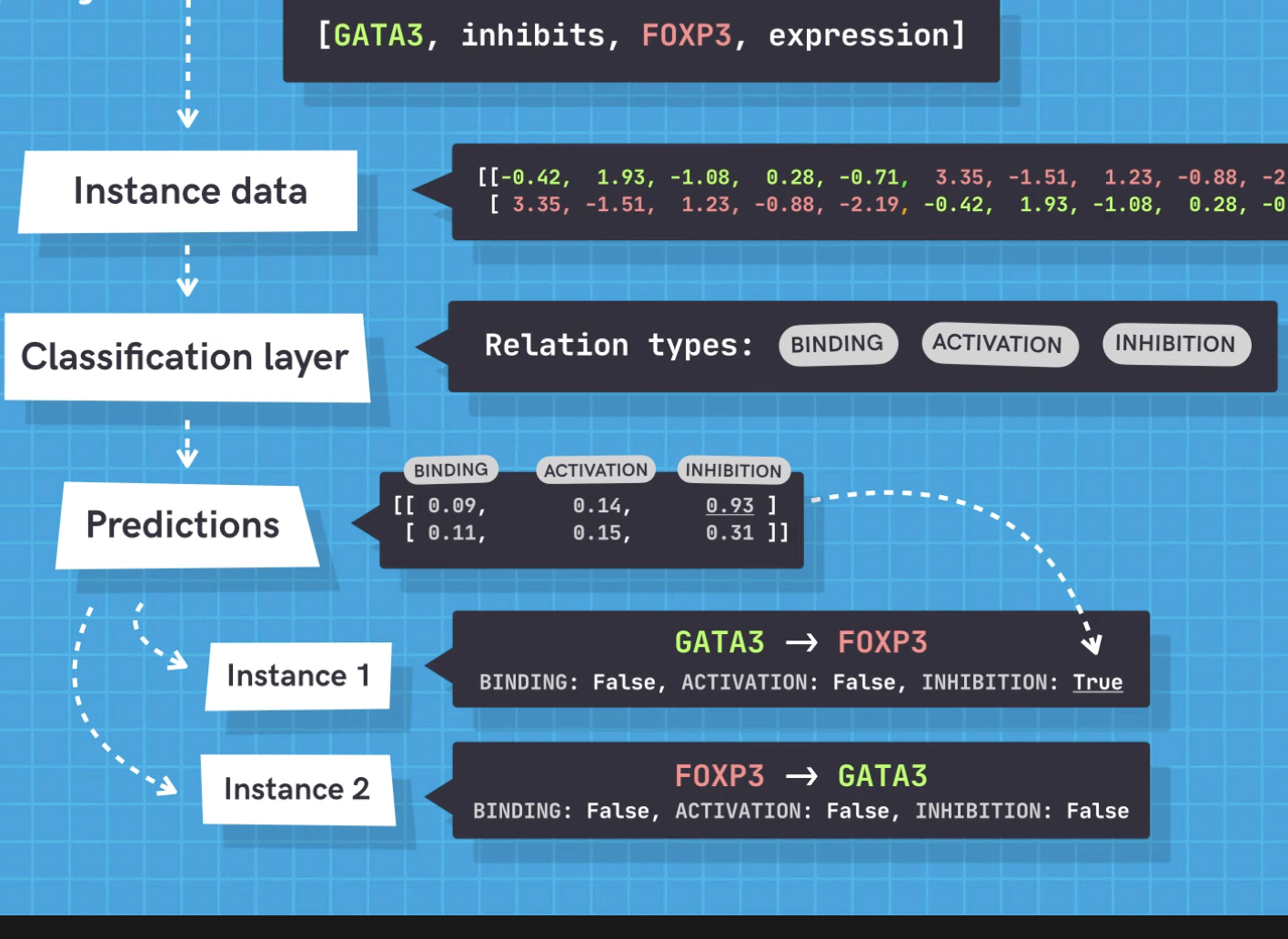
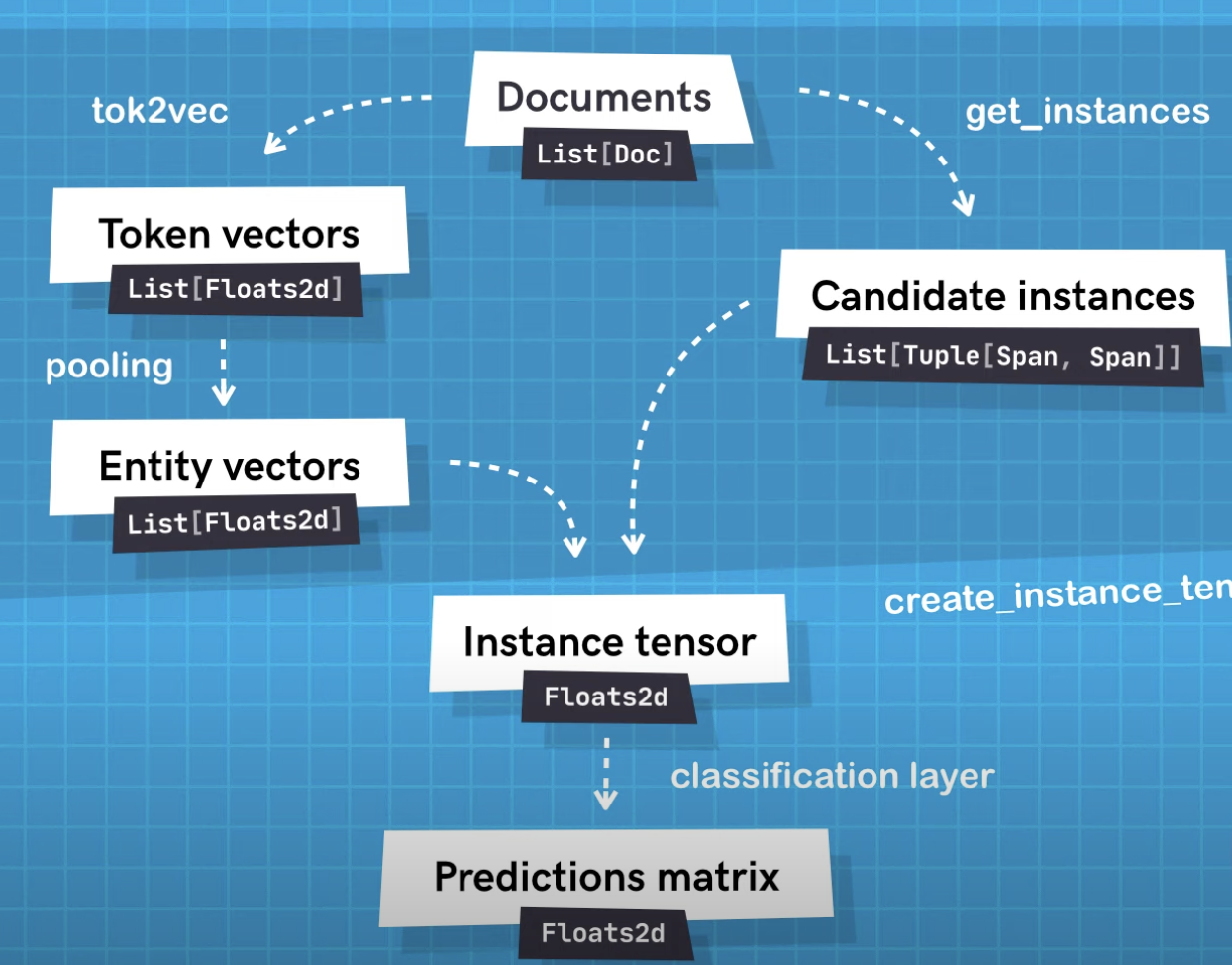
One of the approaches I am using is a SpaCy framework in which you can use pre-trained transformers from hugging Face library and tok2vec.
Here is the work flow: