The goal of unsupervised relation extraction is to extract relations from the web when we have no labeled training data, and not even any list of relations. This task is often called open information extraction or Open IE. In Open IE, the relations are simply strings of words (usually beginning with a verb). For e.g.
Kate lives in Delhi.
Here 2 entities will be extracted Kate and Delhi with the relation lives in . The triples would be {lives in, Kate, Delhi}.
But here since the Sentence is simple so the relation extraction was easy.
Sentences can be classified into 4 types mostly:
- Simple sentence: A sentence which has only one independent clause and no dependent clauses. For e.g.
Kate lives in Delhi.
He runs.
Berlin wall after sometimes was referred as “Iron Curtain”.
- Compound sentence: A sentence which has at least two independent clauses which are combined with a coordinating conjunction. For e.g.
Kate lives in Delhi but works in Bombay.
Kate loves to eat pizza and pasta.
- Complex sentence: A complex sentence which has one or more dependent clauses (subordinate clauses). A dependent clause cannot stand alone. Therefore, a complex sentence must also have at least one independent clause. These clauses are combined by using subordinate conjunction. For e.g.
Whenever it rains, I like to wear my blue coat.
Despite his bad grades, Albert Einstein won nobel Prize.
- Compound-Complex sentence: A sentence which has two or more independent clauses and one or more dependent clauses. For e.g.
If the ozone layer collapses, humans will suffer and humanity would come to an end soon.
CFG for different types of Sentences
Since here we don’t have to check for the correct syntax. We already are having sentences that have correct semantics and grammatical structure.(Wikipedia articles)
Simple Sentence
Simple_Sentence: NV | NVN | NVM | NVME
N -> noun | det noun | det adj noun | adj noun | pronoun
V -> root verb | auxilary verb root verb | root verb adverb | auxilary verb root verb adverb
M -> prepositon N
E -> M adverb
Compound Sentence
Compound_Sentence: SCS | SCN | SCV | SCVE | SCVEM | SCVME
S -> Simple Sentence
C -> coordinating conj
N -> noun | det noun | det adj noun | adj noun | pronoun
V -> root verb | auxilary verb root verb | root verb adverb | auxilary verb root verb adverb
M -> prepositon N
E -> M adverb
Other types of Sentences
Break complex and compound into simpler sentences and rephrase the sentences. For e.g.
While I am a passionate basketball fan, I prefer football.
It should be rephrased to:
I am a passionate basketball fan.
I prefer football.
And now for simpler sentences: Remove adjectives, adverb, determiners and other modifiers. For e.g.
The big fat cat is dancing on the top of the white table happily.
If I remove modifiers, my sentence would be:
Cat is dancing on top of table.
And now take the sentance:
Cat is dancing on the table.
Here Both the sentences would give us the same output relation i.e. {dancing on, Cat, Table}
But in case of the sentence where many adjectives there. We can add those modifiers as a part of subject and object only bn keeping the modifiers stored and then after the process of relation extraction is done again attaching them with the subject and the object.
For instance {dancing on, The Big fat Cat, top of white table}
In some cases, adding modifiers to the subject and object after extracting relation won’t matter much but in cases like
Kate prefers morning flights through Delhi.
In this case, if we remove modifiers, we will end up with this relation: {prefers, Kate, flights}. That is a kind of coarse relation extraction here. But if we add the removed modifiers back in the subject and object, we will get more fine result like: {prefers, Kate, morning flights}. Since filghts can be running at evening, afternoon and night also so it would be good if we are precise with the type of flight she is preferring.
After removing modifiers, we can extract relation simply by extracting where the POS tag is a VERB.
In a simple sentence only one ‘nsubj’ or ‘nsubjpass’ is there. Hence a sentence contains more than one ‘nsubj’ or ‘nsubjpass’ is considered as other than simple sentence.
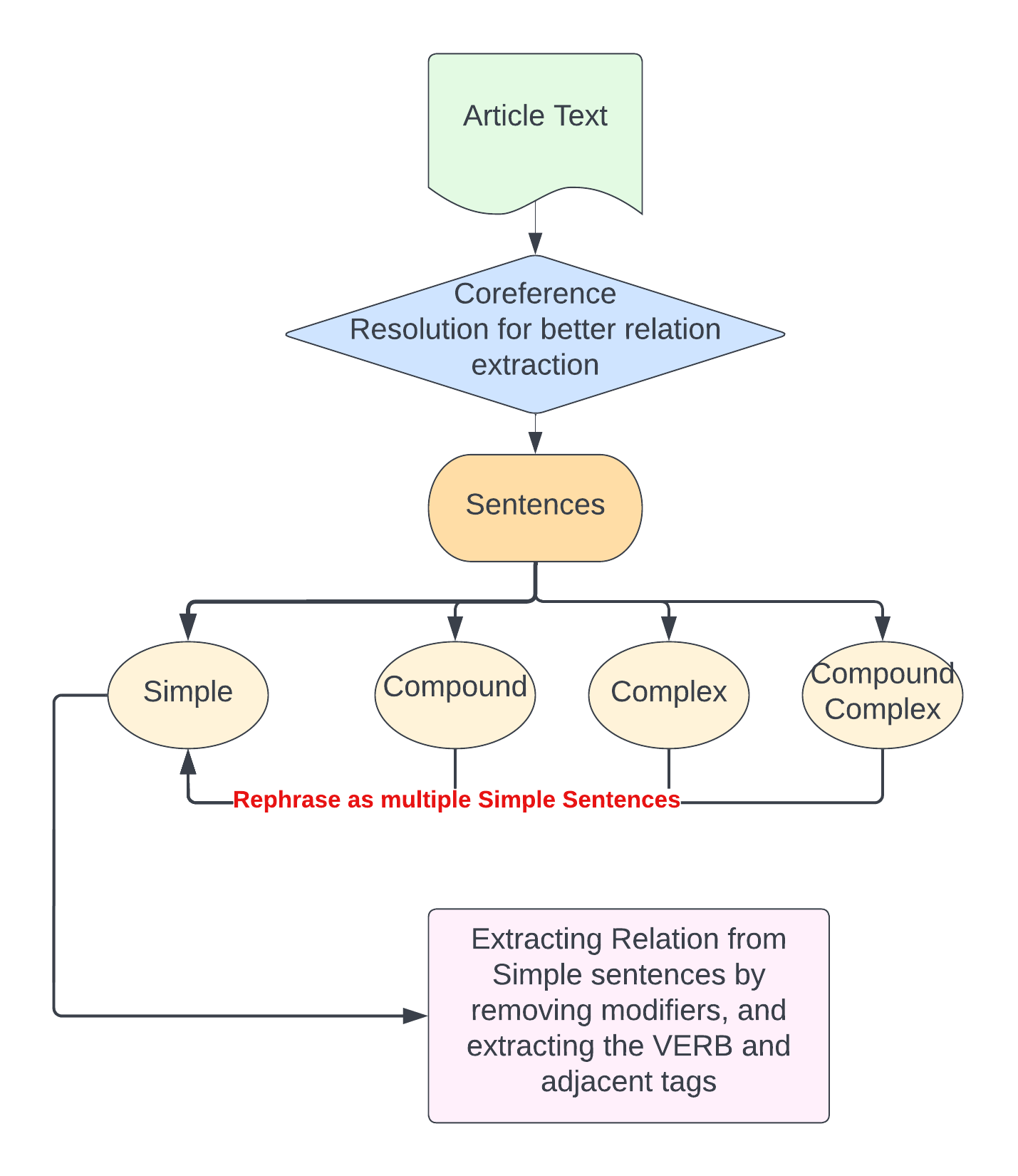 Fig1
Fig1
Dependency Parsing
Relations among the words are illustrated above the sentence with directed, labeled arcs from heads to dependents. A root node explicitly marks the root of the tree, the head of the entire structure.
The fat cat is dancing on the top of white table
 Fig2
Fig2
 Fig3
Fig3
ReVerb System:
It uses dependency parsing only, the ReVerb system extracts a relation from a sentence s in 4 steps:
- Run a part-of-speech tagger and entity chunker over s
- For each verb in s, find the longest sequence of words w that start with a verb and satisfy syntactic and lexical constraints, merging adjacent matches.
- For each phrase w, find the nearest noun phrase x to the left which is not a relative pronoun, wh-word or existential “there”. Find the nearest noun phrase y to the right.
- Assign confidence c to the relation r = (x, w, y) using a confidence classifier and return it.
We can use dependency tokens rather than POS tokens because than we can directly target modifiers like amod, that can provide us an easy way. If using POS tokens then have to write many conditions in order to order to identify a modifier.
 Fig4
Fig4
Rolling Stone hit Kate
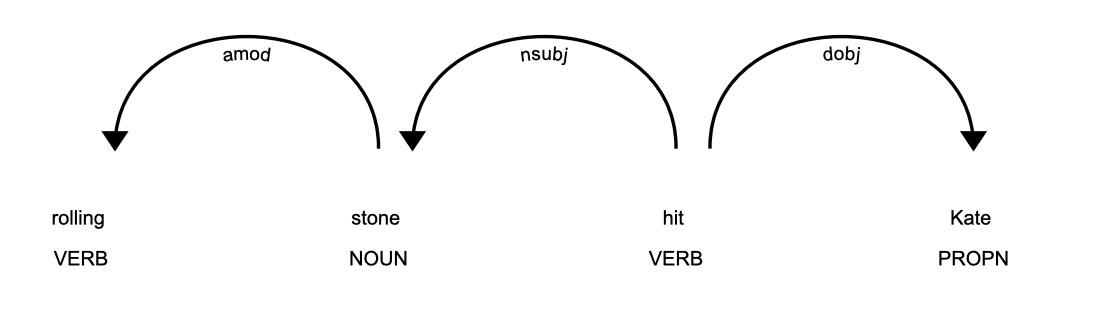 Fig5
Fig5
Here Rolling is identified as a VERB but act as an adjective rather. These type of words are called as gerunds. Often people too confuse them as verb but since this verb is before noun and providing a description about the noun hence acting as a adjective.
In the case,
Stone was rolling down the hill.
Here rolling is a VERB and not a modifier.
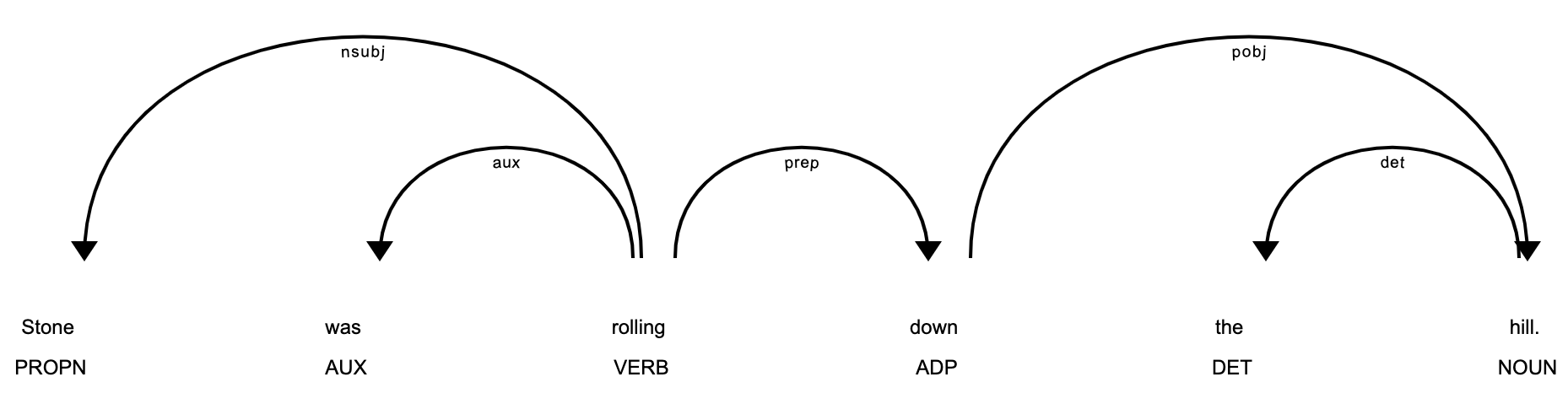 Fig5
Fig5
Ponder
- We have already defined entities that are the pre-defined entities (extracted by running SPARQL query)
- We have text scraped from Wikipidea. That is a whole lot of Text. Use coreference resolution or other tool and restructure/rephrase the text according to the needs but keeping the context of the text same.(wherever referencing to Berlin Wall replace those pronoun’s with Berlin Wall).