Its been 2 days since the GSoC coding period started and this is a blog to keep me and my mentors updated about my work. In these 2 days, I mostly looked into Knowledge Bases and went through some papers, I believe I have acquired the right dataset for training the model and would proceed with that only. Before starting off with distant supervision, it must for me atleast to know a little bit of other methods too and here is a brief summary and limitations for those methods.
Supervised
Supervised approaches use manually labelled training and test data. Those approaches are often specific for or biased towards a certain domain or type of text. This is because information extraction approaches tend to have a higher performance if training and test data are restricted to the same narrow domain. In addition, developing supervised approaches for different domains requires even more manual effort.
Unsupervised
Unsupervised approaches do not need any annotated data for training and instead extract words between entity mentions, then cluster similar word sequences and generalise them to relations. Although unsupervised approaches can process very large amounts of data, the resulting relations are hard to map to ontologies. In addition, it has been documented that these approaches often produce uninformative as well as incoherent extractions.
Semi-supervised
Semi-supervised methods only require a small number of seed instances. The hand-crafted seeds are used to extract patterns from a large corpus, which are then used to extract more instances and again to extract new patterns in an iterative way. The selection of initial seeds is very challenging - if they do not accurately reflect the knowledge contained in the corpus, the quality of extractions might be low. In addition, since many iterations are needed, these methods are prone to semantic drift, i.e. an unwanted shift of meaning. This means these methods require a certain amount of human effort - to create seeds initially and also to help keep systems “on track” to prevent them from semantic drift.
Distant Supervision
The fourth group of approaches are distant supervision or self-supervised learning approaches. The idea is to exploit large knowledge bases (such as Freebase [4]) to auto- matically label entities in text and use the annotated text to extract features and train a classifier. Unlike supervised systems, these approaches do not require manual effort to label data and can be applied to large corpora. Since they extract relations which are defined by vocabularies, these approaches are less likely to produce uninformative or incoherent relations. The resulting distantly-supervised training samples are often very noisy.
Hypothesis of Distant Supervision
Distant supervision is based on the hypothesis, If 2 entities participate in a relation, any sentence that contains those 2 entities might express that relation.
Limitations of Distant supervision, I came to know as of now:
This is a powerful idea, but it has two limitations. The first is that, inevitably, some of the sentences in which “SpaceX” and “Elon Musk” co-occur will not express the founder relation. By making the blind assumption that all such sentences do express the founder relation, we are essentially injecting noise into our training data, and making it harder for our learning algorithms to learn good models. Distant supervision is effective in spite of this problem because it makes it possible to leverage vastly greater quantities of training data, and the benefit of more data outweighs the harm of noisier data. The second limitation is that we need an existing KB to start from. We can only train a model to extract new instances of the founders relation if we already have many instances of the founders relation. Thus, while distant supervision is a great way to extend an existing KB, it’s not useful for creating a KB containing new relations from scratch.
Approach:
- Acquiring training dataset
- Pipeline
- Text preprocessing
- Candidate Generation
- Featurization
- Learning extractors
- Evaluation
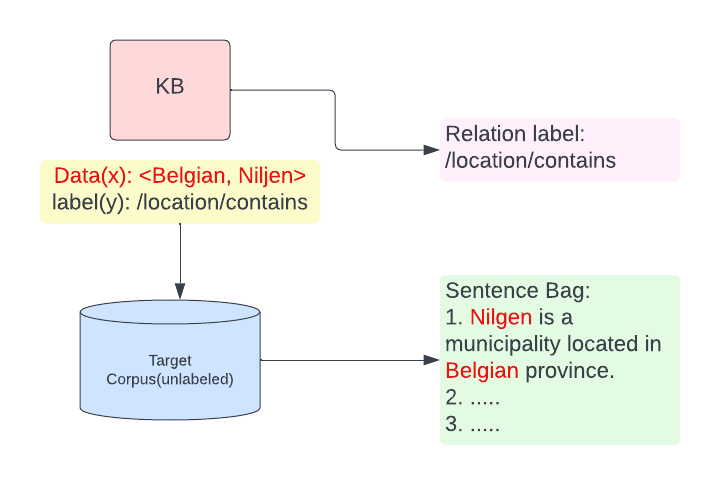 Fig1
Fig1
An interesting Paper on Distant Supervision
I came across a paper, too having an approach on the similar lines, this is its jist: They are using Freebase DB which contains 116 million instances of 7,300 relations b/w 9 million entities.
- In the new text, run NER on text.
- Check for sentences whose Named Entities(tagged earlier) participate in a known freebase relation.
- Since many sentences might cover such relation, we will have many new potential features. Larger the text more the potential sentences.
- Now form a Logistic classifier for those new sentences which map to relation.
Notes
- Relations are fixed? Meaning the relation defined in Freebase DB can only be used.
- Algorithm is supervised by the Database rather than supervised by labelled text.
- Since we are using Freebase relations instead of hand-labelled ones, it does not suffer from overfitting based on domain.
Our classifier takes as input an entity pair and a feature vector and returns a relation name and a confidence score based on the probability of the entity pair belonging to that relation. Once all of the entity pairs discovered during testing have been classified, they can be ranked by confidence score and used to generate a list of the most likely new relation instances.
What are the Features here?
(relation, entity1, entity2) - which is our goal
Here we preprocess the sentence containing the entity using the below features
Given below are the features
- Lexical - Each Lexical feature contains conjunction of all the below components
- The sequence of words between the two entities
- The part-of-speech tags of these words
- A flag indicating which entity came first in the sentence
- A window of k words to the left of Entity 1 and their part-of-speech tags
- A window of k words to the right of Entity 2 and their part-of-speech tags
- Syntactic - Use dependency parser. They consist of the conjunction of
- A dependency path between the two entities
- For each entity, one ‘window’ node that is not part of the dependency path (A window node is a node connected to one of the two entities and not part of the dependency path)
Since we are building a classifier we need to create -ve features also, for that pick random unrelated entity relation from Freebase DB and extract features based on them.